Example usage notebook¶
Objects and functions in this notebook are listed with all paramaters to ilustrate their capabillities. Most of the paramaters have default values in the implementation
Imports¶
import os
import sys
sys.path.append(os.getcwd())
os.chdir("..")
import pandas as pd
import mlflow
pd.set_option("display.max_columns", 200)
pd.set_option("display.max_rows", 300)
import os
import json
from typing import Literal
import pandas as pd
from churn_pred.preprocessing.preprocess import PreprocessData
from churn_pred.training.trainer import Trainer
from churn_pred.training.optuna_optimizer import LGBOptunaOptimizer
from churn_pred.training.utils import flatten_dict, get_or_create_experiment
import dill
import numpy as np
from churn_pred.utils import dill_dump, dill_load
from sklearn.model_selection import train_test_split
from pprint import pprint
Train a testing model¶
# 1. get the data
df_pd = pd.read_parquet("data/dataset_auxiliary_features_cleaned.parquet")
df_pd.head()
| CustomerId | CreditScore | Country | Gender | Age | Tenure | Balance (EUR) | NumberOfProducts | HasCreditCard | IsActiveMember | EstimatedSalary | Exited | CustomerFeedback_sentiment3 | CustomerFeedback_sentiment5 | Surname_Country | Surname_Country_region | Surname_Country_subregion | Country_region | Country_subregion | is_native | Country_hemisphere | Country_gdp_per_capita | Country_IncomeGroup | Surname_Country_gdp_per_capita | Surname_Country_IncomeGroup | working_class | stage_of_life | generation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15787619 | 844 | France | Male | 18 | 2 | 160980.03 | 1 | 0 | 0 | 145936.28 | 0 | neutral | 4 stars | Taiwan | Asia | Eastern Asia | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 32756.00000 | None | working_age | teen | gen_z |
| 1 | 15770309 | 656 | France | Male | 18 | 10 | 151762.74 | 1 | 0 | 1 | 127014.32 | 0 | neutral | 1 star | United States | Americas | Northern America | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 76329.58227 | High income | working_age | teen | gen_z |
| 2 | 15569178 | 570 | France | Female | 18 | 4 | 82767.42 | 1 | 1 | 0 | 71811.90 | 0 | neutral | 2 stars | Russian Federation | Europe | Eastern Europe | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 34637.76172 | Upper middle income | working_age | teen | gen_z |
| 3 | 15795519 | 716 | Germany | Female | 18 | 3 | 128743.80 | 1 | 0 | 0 | 197322.13 | 0 | neutral | 2 stars | Russian Federation | Europe | Eastern Europe | Europe | Western Europe | 0 | northern | 66616.02225 | High income | 34637.76172 | Upper middle income | working_age | teen | gen_z |
| 4 | 15621893 | 727 | France | Male | 18 | 4 | 133550.67 | 1 | 1 | 1 | 46941.41 | 0 | positive | 1 star | Italy | Europe | Southern Europe | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 55442.07843 | High income | working_age | teen | gen_z |
target_col = "Exited"
id_cols = ["CustomerId"]
cat_cols = ["Country", "Gender", "HasCreditCard", "IsActiveMember","CustomerFeedback_sentiment3", "CustomerFeedback_sentiment5", "Surname_Country", "Surname_Country_region", "Surname_Country_subregion", "Country_region", "Country_subregion", "is_native", "Country_hemisphere", "Country_IncomeGroup", "Surname_Country_IncomeGroup", "working_class", "stage_of_life", "generation"]
cont_cols = df_pd.drop(columns=id_cols + cat_cols + [target_col]).columns.values.tolist()
df_pd[cat_cols] = df_pd[cat_cols].astype(str)
valid_size = 0.2
test_size = 0.5
random_state = 1
df_train, df_valid = train_test_split(df_pd, test_size=valid_size, stratify=df_pd[target_col], random_state=random_state)
df_valid, df_test = train_test_split(df_valid, test_size=test_size, stratify=df_valid[target_col], random_state=random_state)
prepare_data = PreprocessData(
id_cols=id_cols,
target_col=target_col,
cat_cols=cat_cols,
cont_cols=cont_cols,
)
# this should be fitted only on training data
_ = prepare_data.fit(df=df_pd)
optimizer = LGBOptunaOptimizer(
objective="binary",
n_class=2,
)
trainer = Trainer(
cat_cols=prepare_data.cat_cols,
target_col=prepare_data.target_col,
id_cols=id_cols,
objective="binary",
n_class=2,
optimizer=optimizer,
preprocessors=[prepare_data],
)
metrics_dict = trainer.fit(
df_train=df_train,
df_valid=df_valid,
df_test=df_test,
)
[I 2024-06-18 21:05:47,850] A new study created in memory with name: no-name-72ade7dc-1867-41c2-b5a4-df3b58765bc7 feature_fraction, val_score: inf: 0%| | 0/7 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.388064: 14%|#4 | 1/7 [00:08<00:48, 8.11s/it][I 2024-06-18 21:05:55,971] Trial 0 finished with value: 0.38806351066689354 and parameters: {'feature_fraction': 0.4}. Best is trial 0 with value: 0.38806351066689354.
feature_fraction, val_score: 0.388064: 14%|#4 | 1/7 [00:08<00:48, 8.11s/it]
Early stopping, best iteration is: [241] valid_0's binary_logloss: 0.388064 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.384552: 29%|##8 | 2/7 [00:15<00:39, 7.81s/it][I 2024-06-18 21:06:03,568] Trial 1 finished with value: 0.38455247747199556 and parameters: {'feature_fraction': 0.5}. Best is trial 1 with value: 0.38455247747199556.
feature_fraction, val_score: 0.384552: 29%|##8 | 2/7 [00:15<00:39, 7.81s/it]
Early stopping, best iteration is: [184] valid_0's binary_logloss: 0.384552 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.381327: 43%|####2 | 3/7 [00:20<00:25, 6.48s/it][I 2024-06-18 21:06:08,471] Trial 2 finished with value: 0.3813271028603074 and parameters: {'feature_fraction': 0.8}. Best is trial 2 with value: 0.3813271028603074.
feature_fraction, val_score: 0.381327: 43%|####2 | 3/7 [00:20<00:25, 6.48s/it]
Early stopping, best iteration is: [154] valid_0's binary_logloss: 0.381327 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.381327: 57%|#####7 | 4/7 [00:22<00:13, 4.64s/it][I 2024-06-18 21:06:10,281] Trial 3 finished with value: 0.40303264639386804 and parameters: {'feature_fraction': 0.8999999999999999}. Best is trial 2 with value: 0.3813271028603074.
feature_fraction, val_score: 0.381327: 57%|#####7 | 4/7 [00:22<00:13, 4.64s/it]
Early stopping, best iteration is: [9] valid_0's binary_logloss: 0.403033 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.381327: 71%|#######1 | 5/7 [00:29<00:10, 5.45s/it][I 2024-06-18 21:06:17,181] Trial 4 finished with value: 0.385808915879594 and parameters: {'feature_fraction': 1.0}. Best is trial 2 with value: 0.3813271028603074.
feature_fraction, val_score: 0.381327: 71%|#######1 | 5/7 [00:29<00:10, 5.45s/it]
Early stopping, best iteration is: [196] valid_0's binary_logloss: 0.385809 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.381327: 86%|########5 | 6/7 [00:35<00:05, 5.57s/it][I 2024-06-18 21:06:22,970] Trial 5 finished with value: 0.3905588715180784 and parameters: {'feature_fraction': 0.7}. Best is trial 2 with value: 0.3813271028603074.
feature_fraction, val_score: 0.381327: 86%|########5 | 6/7 [00:35<00:05, 5.57s/it]
Early stopping, best iteration is: [152] valid_0's binary_logloss: 0.390559 Training until validation scores don't improve for 50 rounds
feature_fraction, val_score: 0.381327: 100%|##########| 7/7 [00:41<00:00, 5.97s/it][I 2024-06-18 21:06:29,778] Trial 6 finished with value: 0.38245734022417816 and parameters: {'feature_fraction': 0.6}. Best is trial 2 with value: 0.3813271028603074.
feature_fraction, val_score: 0.381327: 100%|##########| 7/7 [00:41<00:00, 5.99s/it]
Early stopping, best iteration is: [201] valid_0's binary_logloss: 0.382457
num_leaves, val_score: 0.381327: 0%| | 0/20 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.381327: 5%|5 | 1/20 [00:06<02:12, 6.99s/it][I 2024-06-18 21:06:36,772] Trial 7 finished with value: 0.3867130065464061 and parameters: {'num_leaves': 28}. Best is trial 7 with value: 0.3867130065464061.
num_leaves, val_score: 0.381327: 5%|5 | 1/20 [00:06<02:12, 6.99s/it]
Early stopping, best iteration is: [225] valid_0's binary_logloss: 0.386713 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.370474: 10%|# | 2/20 [00:14<02:15, 7.51s/it][I 2024-06-18 21:06:44,655] Trial 8 finished with value: 0.3704743259843756 and parameters: {'num_leaves': 92}. Best is trial 8 with value: 0.3704743259843756.
num_leaves, val_score: 0.370474: 10%|# | 2/20 [00:14<02:15, 7.51s/it]
Early stopping, best iteration is: [64] valid_0's binary_logloss: 0.370474 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.370474: 15%|#5 | 3/20 [00:26<02:42, 9.53s/it][I 2024-06-18 21:06:56,583] Trial 9 finished with value: 0.3718260260505307 and parameters: {'num_leaves': 149}. Best is trial 8 with value: 0.3704743259843756.
num_leaves, val_score: 0.370474: 15%|#5 | 3/20 [00:26<02:42, 9.53s/it]
Early stopping, best iteration is: [49] valid_0's binary_logloss: 0.371826 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.370474: 20%|## | 4/20 [00:44<03:21, 12.59s/it][I 2024-06-18 21:07:13,876] Trial 10 finished with value: 0.37095297012345396 and parameters: {'num_leaves': 248}. Best is trial 8 with value: 0.3704743259843756.
num_leaves, val_score: 0.370474: 20%|## | 4/20 [00:44<03:21, 12.59s/it]
Early stopping, best iteration is: [41] valid_0's binary_logloss: 0.370953 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.370474: 25%|##5 | 5/20 [00:59<03:25, 13.71s/it][I 2024-06-18 21:07:29,563] Trial 11 finished with value: 0.3738263141664088 and parameters: {'num_leaves': 252}. Best is trial 8 with value: 0.3704743259843756.
num_leaves, val_score: 0.370474: 25%|##5 | 5/20 [00:59<03:25, 13.71s/it]
Early stopping, best iteration is: [46] valid_0's binary_logloss: 0.373826 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.370474: 30%|### | 6/20 [01:08<02:48, 12.01s/it][I 2024-06-18 21:07:38,283] Trial 12 finished with value: 0.38055573216311783 and parameters: {'num_leaves': 96}. Best is trial 8 with value: 0.3704743259843756.
num_leaves, val_score: 0.370474: 30%|### | 6/20 [01:08<02:48, 12.01s/it]
Early stopping, best iteration is: [52] valid_0's binary_logloss: 0.380556 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 35%|###5 | 7/20 [01:25<02:58, 13.73s/it][I 2024-06-18 21:07:55,556] Trial 13 finished with value: 0.36708245318754934 and parameters: {'num_leaves': 253}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 35%|###5 | 7/20 [01:25<02:58, 13.73s/it]
Early stopping, best iteration is: [39] valid_0's binary_logloss: 0.367082 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 40%|#### | 8/20 [01:36<02:33, 12.81s/it][I 2024-06-18 21:08:06,381] Trial 14 finished with value: 0.3760206407150123 and parameters: {'num_leaves': 132}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 40%|#### | 8/20 [01:36<02:33, 12.81s/it]
Early stopping, best iteration is: [51] valid_0's binary_logloss: 0.376021 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 45%|####5 | 9/20 [01:44<02:05, 11.43s/it][I 2024-06-18 21:08:14,782] Trial 15 finished with value: 0.378543416834411 and parameters: {'num_leaves': 64}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 45%|####5 | 9/20 [01:44<02:05, 11.43s/it]
Early stopping, best iteration is: [103] valid_0's binary_logloss: 0.378543 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 50%|##### | 10/20 [01:56<01:55, 11.58s/it][I 2024-06-18 21:08:26,682] Trial 16 finished with value: 0.37346546696167743 and parameters: {'num_leaves': 184}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 50%|##### | 10/20 [01:56<01:55, 11.58s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.373465 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 55%|#####5 | 11/20 [02:08<01:45, 11.67s/it][I 2024-06-18 21:08:38,573] Trial 17 finished with value: 0.3716035258824437 and parameters: {'num_leaves': 178}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 55%|#####5 | 11/20 [02:08<01:45, 11.67s/it]
Early stopping, best iteration is: [33] valid_0's binary_logloss: 0.371604 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 60%|###### | 12/20 [02:10<01:08, 8.58s/it][I 2024-06-18 21:08:40,079] Trial 18 finished with value: 0.4090573635738217 and parameters: {'num_leaves': 6}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 60%|###### | 12/20 [02:10<01:08, 8.58s/it]
Early stopping, best iteration is: [219] valid_0's binary_logloss: 0.409057 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 65%|######5 | 13/20 [02:19<01:00, 8.68s/it][I 2024-06-18 21:08:48,983] Trial 19 finished with value: 0.3704743259843756 and parameters: {'num_leaves': 92}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 65%|######5 | 13/20 [02:19<01:00, 8.68s/it]
Early stopping, best iteration is: [64] valid_0's binary_logloss: 0.370474 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 70%|####### | 14/20 [02:34<01:03, 10.58s/it][I 2024-06-18 21:09:03,972] Trial 20 finished with value: 0.37479451809569353 and parameters: {'num_leaves': 211}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 70%|####### | 14/20 [02:34<01:03, 10.58s/it]
Early stopping, best iteration is: [38] valid_0's binary_logloss: 0.374795 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 75%|#######5 | 15/20 [02:43<00:50, 10.14s/it][I 2024-06-18 21:09:13,084] Trial 21 finished with value: 0.3772431537086629 and parameters: {'num_leaves': 90}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 75%|#######5 | 15/20 [02:43<00:50, 10.14s/it]
Early stopping, best iteration is: [69] valid_0's binary_logloss: 0.377243 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 80%|######## | 16/20 [02:53<00:40, 10.13s/it][I 2024-06-18 21:09:23,178] Trial 22 finished with value: 0.3728508215083201 and parameters: {'num_leaves': 94}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 80%|######## | 16/20 [02:53<00:40, 10.13s/it]
Early stopping, best iteration is: [76] valid_0's binary_logloss: 0.372851 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 85%|########5 | 17/20 [03:01<00:28, 9.57s/it][I 2024-06-18 21:09:31,462] Trial 23 finished with value: 0.3741261012500593 and parameters: {'num_leaves': 65}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 85%|########5 | 17/20 [03:01<00:28, 9.57s/it]
Early stopping, best iteration is: [130] valid_0's binary_logloss: 0.374126 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 90%|######### | 18/20 [03:11<00:19, 9.61s/it][I 2024-06-18 21:09:41,151] Trial 24 finished with value: 0.3809976671401048 and parameters: {'num_leaves': 116}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 90%|######### | 18/20 [03:11<00:19, 9.61s/it]
Early stopping, best iteration is: [61] valid_0's binary_logloss: 0.380998 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 95%|#########5| 19/20 [03:18<00:08, 8.92s/it][I 2024-06-18 21:09:48,483] Trial 25 finished with value: 0.3773659816174925 and parameters: {'num_leaves': 45}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 95%|#########5| 19/20 [03:18<00:08, 8.92s/it]
Early stopping, best iteration is: [150] valid_0's binary_logloss: 0.377366 Training until validation scores don't improve for 50 rounds
num_leaves, val_score: 0.367082: 100%|##########| 20/20 [03:27<00:00, 8.98s/it][I 2024-06-18 21:09:57,579] Trial 26 finished with value: 0.379797423356925 and parameters: {'num_leaves': 148}. Best is trial 13 with value: 0.36708245318754934.
num_leaves, val_score: 0.367082: 100%|##########| 20/20 [03:27<00:00, 10.39s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.379797
bagging, val_score: 0.367082: 0%| | 0/10 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 10%|# | 1/10 [00:15<02:17, 15.28s/it][I 2024-06-18 21:10:12,864] Trial 27 finished with value: 0.3754694447762392 and parameters: {'bagging_fraction': 0.6017118946353502, 'bagging_freq': 3}. Best is trial 27 with value: 0.3754694447762392.
bagging, val_score: 0.367082: 10%|# | 1/10 [00:15<02:17, 15.28s/it]
Early stopping, best iteration is: [54] valid_0's binary_logloss: 0.375469 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 20%|## | 2/10 [00:32<02:10, 16.29s/it][I 2024-06-18 21:10:29,858] Trial 28 finished with value: 0.37140708223458174 and parameters: {'bagging_fraction': 0.9697760068067878, 'bagging_freq': 7}. Best is trial 28 with value: 0.37140708223458174.
bagging, val_score: 0.367082: 20%|## | 2/10 [00:32<02:10, 16.29s/it]
Early stopping, best iteration is: [51] valid_0's binary_logloss: 0.371407 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 30%|### | 3/10 [00:40<01:27, 12.51s/it][I 2024-06-18 21:10:37,880] Trial 29 finished with value: 0.3763001794627212 and parameters: {'bagging_fraction': 0.4336686702739523, 'bagging_freq': 1}. Best is trial 28 with value: 0.37140708223458174.
bagging, val_score: 0.367082: 30%|### | 3/10 [00:40<01:27, 12.51s/it]
Early stopping, best iteration is: [35] valid_0's binary_logloss: 0.3763 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 40%|#### | 4/10 [00:57<01:25, 14.27s/it][I 2024-06-18 21:10:54,855] Trial 30 finished with value: 0.37399860180838584 and parameters: {'bagging_fraction': 0.9955847594220013, 'bagging_freq': 7}. Best is trial 28 with value: 0.37140708223458174.
bagging, val_score: 0.367082: 40%|#### | 4/10 [00:57<01:25, 14.27s/it]
Early stopping, best iteration is: [46] valid_0's binary_logloss: 0.373999 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 50%|##### | 5/10 [01:13<01:15, 15.04s/it][I 2024-06-18 21:11:11,265] Trial 31 finished with value: 0.36851832518824595 and parameters: {'bagging_fraction': 0.7559826069760041, 'bagging_freq': 4}. Best is trial 31 with value: 0.36851832518824595.
bagging, val_score: 0.367082: 50%|##### | 5/10 [01:13<01:15, 15.04s/it]
Early stopping, best iteration is: [46] valid_0's binary_logloss: 0.368518 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 60%|###### | 6/10 [01:29<01:00, 15.17s/it][I 2024-06-18 21:11:26,675] Trial 32 finished with value: 0.3695574686675923 and parameters: {'bagging_fraction': 0.7373615298502163, 'bagging_freq': 4}. Best is trial 31 with value: 0.36851832518824595.
bagging, val_score: 0.367082: 60%|###### | 6/10 [01:29<01:00, 15.17s/it]
Early stopping, best iteration is: [51] valid_0's binary_logloss: 0.369557 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 70%|####### | 7/10 [01:44<00:45, 15.17s/it][I 2024-06-18 21:11:41,852] Trial 33 finished with value: 0.37298644850012186 and parameters: {'bagging_fraction': 0.7616544959864899, 'bagging_freq': 4}. Best is trial 31 with value: 0.36851832518824595.
bagging, val_score: 0.367082: 70%|####### | 7/10 [01:44<00:45, 15.17s/it]
Early stopping, best iteration is: [38] valid_0's binary_logloss: 0.372986 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 80%|######## | 8/10 [01:58<00:29, 14.94s/it][I 2024-06-18 21:11:56,282] Trial 34 finished with value: 0.3745164899611851 and parameters: {'bagging_fraction': 0.7510199039916521, 'bagging_freq': 5}. Best is trial 31 with value: 0.36851832518824595.
bagging, val_score: 0.367082: 80%|######## | 8/10 [01:58<00:29, 14.94s/it]
Early stopping, best iteration is: [35] valid_0's binary_logloss: 0.374516 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 90%|######### | 9/10 [02:13<00:14, 14.95s/it][I 2024-06-18 21:12:11,256] Trial 35 finished with value: 0.3790678087224149 and parameters: {'bagging_fraction': 0.6376411296778922, 'bagging_freq': 3}. Best is trial 31 with value: 0.36851832518824595.
bagging, val_score: 0.367082: 90%|######### | 9/10 [02:13<00:14, 14.95s/it]
Early stopping, best iteration is: [41] valid_0's binary_logloss: 0.379068 Training until validation scores don't improve for 50 rounds
bagging, val_score: 0.367082: 100%|##########| 10/10 [02:28<00:00, 14.82s/it][I 2024-06-18 21:12:25,777] Trial 36 finished with value: 0.36759282443526115 and parameters: {'bagging_fraction': 0.8438639692641409, 'bagging_freq': 5}. Best is trial 36 with value: 0.36759282443526115.
bagging, val_score: 0.367082: 100%|##########| 10/10 [02:28<00:00, 14.82s/it]
Early stopping, best iteration is: [30] valid_0's binary_logloss: 0.367593
feature_fraction_stage2, val_score: 0.367082: 0%| | 0/6 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.367082: 17%|#6 | 1/6 [00:14<01:11, 14.28s/it][I 2024-06-18 21:12:40,067] Trial 37 finished with value: 0.3751194682458601 and parameters: {'feature_fraction': 0.8480000000000001}. Best is trial 37 with value: 0.3751194682458601.
feature_fraction_stage2, val_score: 0.367082: 17%|#6 | 1/6 [00:14<01:11, 14.28s/it]
Early stopping, best iteration is: [31] valid_0's binary_logloss: 0.375119 Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.367082: 33%|###3 | 2/6 [00:31<01:03, 15.82s/it][I 2024-06-18 21:12:56,969] Trial 38 finished with value: 0.37511946824586 and parameters: {'feature_fraction': 0.88}. Best is trial 38 with value: 0.37511946824586.
feature_fraction_stage2, val_score: 0.367082: 33%|###3 | 2/6 [00:31<01:03, 15.82s/it]
Early stopping, best iteration is: [31] valid_0's binary_logloss: 0.375119 Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.367082: 50%|##### | 3/6 [00:48<00:50, 16.73s/it][I 2024-06-18 21:13:14,771] Trial 39 finished with value: 0.37230053743309227 and parameters: {'feature_fraction': 0.7520000000000001}. Best is trial 39 with value: 0.37230053743309227.
feature_fraction_stage2, val_score: 0.367082: 50%|##### | 3/6 [00:48<00:50, 16.73s/it]
Early stopping, best iteration is: [46] valid_0's binary_logloss: 0.372301 Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.367082: 67%|######6 | 4/6 [01:05<00:33, 16.76s/it][I 2024-06-18 21:13:31,580] Trial 40 finished with value: 0.37230053743309227 and parameters: {'feature_fraction': 0.7200000000000001}. Best is trial 39 with value: 0.37230053743309227.
feature_fraction_stage2, val_score: 0.367082: 67%|######6 | 4/6 [01:05<00:33, 16.76s/it]
Early stopping, best iteration is: [46] valid_0's binary_logloss: 0.372301 Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.366281: 83%|########3 | 5/6 [01:21<00:16, 16.48s/it][I 2024-06-18 21:13:47,556] Trial 41 finished with value: 0.3662812971282284 and parameters: {'feature_fraction': 0.8160000000000001}. Best is trial 41 with value: 0.3662812971282284.
feature_fraction_stage2, val_score: 0.366281: 83%|########3 | 5/6 [01:21<00:16, 16.48s/it]
Early stopping, best iteration is: [30] valid_0's binary_logloss: 0.366281 Training until validation scores don't improve for 50 rounds
feature_fraction_stage2, val_score: 0.366281: 100%|##########| 6/6 [01:38<00:00, 16.66s/it][I 2024-06-18 21:14:04,578] Trial 42 finished with value: 0.3670824531875493 and parameters: {'feature_fraction': 0.784}. Best is trial 41 with value: 0.3662812971282284.
feature_fraction_stage2, val_score: 0.366281: 100%|##########| 6/6 [01:38<00:00, 16.47s/it]
Early stopping, best iteration is: [39] valid_0's binary_logloss: 0.367082
regularization_factors, val_score: 0.366281: 0%| | 0/20 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 5%|5 | 1/20 [00:13<04:12, 13.29s/it][I 2024-06-18 21:14:17,877] Trial 43 finished with value: 0.36913074695699283 and parameters: {'lambda_l1': 0.26740014043884963, 'lambda_l2': 0.001760870184331642}. Best is trial 43 with value: 0.36913074695699283.
regularization_factors, val_score: 0.366281: 5%|5 | 1/20 [00:13<04:12, 13.29s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.369131 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 10%|# | 2/20 [00:28<04:21, 14.52s/it][I 2024-06-18 21:14:33,256] Trial 44 finished with value: 0.3744642189562516 and parameters: {'lambda_l1': 1.1442585672872564e-08, 'lambda_l2': 4.849247272391423e-08}. Best is trial 43 with value: 0.36913074695699283.
regularization_factors, val_score: 0.366281: 10%|# | 2/20 [00:28<04:21, 14.52s/it]
Early stopping, best iteration is: [37] valid_0's binary_logloss: 0.374464 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 15%|#5 | 3/20 [00:45<04:23, 15.52s/it][I 2024-06-18 21:14:49,962] Trial 45 finished with value: 0.3703169935094016 and parameters: {'lambda_l1': 9.96832677827828e-07, 'lambda_l2': 6.3332349736895}. Best is trial 43 with value: 0.36913074695699283.
regularization_factors, val_score: 0.366281: 15%|#5 | 3/20 [00:45<04:23, 15.52s/it]
Early stopping, best iteration is: [75] valid_0's binary_logloss: 0.370317 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 20%|## | 4/20 [00:58<03:54, 14.69s/it][I 2024-06-18 21:15:03,375] Trial 46 finished with value: 0.3672993919740384 and parameters: {'lambda_l1': 1.5127153863704856, 'lambda_l2': 4.478393628964223e-08}. Best is trial 46 with value: 0.3672993919740384.
regularization_factors, val_score: 0.366281: 20%|## | 4/20 [00:58<03:54, 14.69s/it]
Early stopping, best iteration is: [49] valid_0's binary_logloss: 0.367299 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 25%|##5 | 5/20 [01:12<03:36, 14.40s/it][I 2024-06-18 21:15:17,268] Trial 47 finished with value: 0.3673221145565776 and parameters: {'lambda_l1': 2.3927205612539093, 'lambda_l2': 5.0167732343674086e-08}. Best is trial 46 with value: 0.3672993919740384.
regularization_factors, val_score: 0.366281: 25%|##5 | 5/20 [01:12<03:36, 14.40s/it]
Early stopping, best iteration is: [73] valid_0's binary_logloss: 0.367322 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.366281: 30%|### | 6/20 [01:25<03:15, 13.96s/it][I 2024-06-18 21:15:30,372] Trial 48 finished with value: 0.38611937264133733 and parameters: {'lambda_l1': 6.054665616489558, 'lambda_l2': 1.800720533496738e-08}. Best is trial 46 with value: 0.3672993919740384.
regularization_factors, val_score: 0.366281: 30%|### | 6/20 [01:25<03:15, 13.96s/it]
Early stopping, best iteration is: [156] valid_0's binary_logloss: 0.386119 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 35%|###5 | 7/20 [01:41<03:08, 14.53s/it][I 2024-06-18 21:15:46,069] Trial 49 finished with value: 0.36481873368079354 and parameters: {'lambda_l1': 0.018981605475779886, 'lambda_l2': 4.496278591408666e-06}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 35%|###5 | 7/20 [01:41<03:08, 14.53s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.364819 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 40%|#### | 8/20 [01:58<03:02, 15.22s/it][I 2024-06-18 21:16:02,773] Trial 50 finished with value: 0.3676098962913463 and parameters: {'lambda_l1': 0.005938438143650016, 'lambda_l2': 1.6486829620090715e-05}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 40%|#### | 8/20 [01:58<03:02, 15.22s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.36761 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 45%|####5 | 9/20 [02:13<02:46, 15.12s/it][I 2024-06-18 21:16:17,683] Trial 51 finished with value: 0.3693663505867317 and parameters: {'lambda_l1': 0.14870260759215176, 'lambda_l2': 8.827878170241735e-07}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 45%|####5 | 9/20 [02:13<02:46, 15.12s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.369366 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 50%|##### | 10/20 [02:21<02:11, 13.17s/it][I 2024-06-18 21:16:26,468] Trial 52 finished with value: 0.3995526935417914 and parameters: {'lambda_l1': 9.914097223337537, 'lambda_l2': 2.507766754016921e-06}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 50%|##### | 10/20 [02:21<02:11, 13.17s/it]
Early stopping, best iteration is: [108] valid_0's binary_logloss: 0.399553 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 55%|#####5 | 11/20 [02:36<02:02, 13.60s/it][I 2024-06-18 21:16:41,058] Trial 53 finished with value: 0.37135627608204047 and parameters: {'lambda_l1': 0.004317296224576123, 'lambda_l2': 1.0694628305152963e-08}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 55%|#####5 | 11/20 [02:36<02:02, 13.60s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.371356 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 60%|###### | 12/20 [02:50<01:50, 13.82s/it][I 2024-06-18 21:16:55,362] Trial 54 finished with value: 0.3656757773203038 and parameters: {'lambda_l1': 0.1528681952118711, 'lambda_l2': 0.0003078435151438368}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 60%|###### | 12/20 [02:50<01:50, 13.82s/it]
Early stopping, best iteration is: [38] valid_0's binary_logloss: 0.365676 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 65%|######5 | 13/20 [03:03<01:34, 13.48s/it][I 2024-06-18 21:17:08,074] Trial 55 finished with value: 0.3683612678266087 and parameters: {'lambda_l1': 0.026844520069898837, 'lambda_l2': 0.0010041201106681954}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 65%|######5 | 13/20 [03:03<01:34, 13.48s/it]
Early stopping, best iteration is: [30] valid_0's binary_logloss: 0.368361 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 70%|####### | 14/20 [03:18<01:24, 14.03s/it][I 2024-06-18 21:17:23,369] Trial 56 finished with value: 0.367596997615459 and parameters: {'lambda_l1': 0.0003242973314637712, 'lambda_l2': 5.561136449228501e-05}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 70%|####### | 14/20 [03:18<01:24, 14.03s/it]
Early stopping, best iteration is: [30] valid_0's binary_logloss: 0.367597 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 75%|#######5 | 15/20 [03:31<01:07, 13.57s/it][I 2024-06-18 21:17:35,879] Trial 57 finished with value: 0.36589916181880006 and parameters: {'lambda_l1': 0.2057156258629452, 'lambda_l2': 0.024885518547422405}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 75%|#######5 | 15/20 [03:31<01:07, 13.57s/it]
Early stopping, best iteration is: [31] valid_0's binary_logloss: 0.365899 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 80%|######## | 16/20 [03:45<00:55, 13.85s/it][I 2024-06-18 21:17:50,372] Trial 58 finished with value: 0.36736185428940016 and parameters: {'lambda_l1': 0.0002150419853087141, 'lambda_l2': 0.034107683119902095}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 80%|######## | 16/20 [03:45<00:55, 13.85s/it]
Early stopping, best iteration is: [34] valid_0's binary_logloss: 0.367362 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 85%|########5 | 17/20 [04:00<00:42, 14.20s/it][I 2024-06-18 21:18:05,384] Trial 59 finished with value: 0.3702898033719683 and parameters: {'lambda_l1': 0.0583471784381045, 'lambda_l2': 0.3274496387110711}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 85%|########5 | 17/20 [04:00<00:42, 14.20s/it]
Early stopping, best iteration is: [40] valid_0's binary_logloss: 0.37029 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 90%|######### | 18/20 [04:18<00:30, 15.10s/it][I 2024-06-18 21:18:22,586] Trial 60 finished with value: 0.3651493917986752 and parameters: {'lambda_l1': 0.001458069822509784, 'lambda_l2': 0.008248248782706902}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 90%|######### | 18/20 [04:18<00:30, 15.10s/it]
Early stopping, best iteration is: [43] valid_0's binary_logloss: 0.365149 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 95%|#########5| 19/20 [04:33<00:15, 15.10s/it][I 2024-06-18 21:18:37,676] Trial 61 finished with value: 0.3696068718370661 and parameters: {'lambda_l1': 0.0006748569060520587, 'lambda_l2': 0.01603839211588336}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 95%|#########5| 19/20 [04:33<00:15, 15.10s/it]
Early stopping, best iteration is: [41] valid_0's binary_logloss: 0.369607 Training until validation scores don't improve for 50 rounds
regularization_factors, val_score: 0.364819: 100%|##########| 20/20 [04:48<00:00, 15.16s/it][I 2024-06-18 21:18:52,985] Trial 62 finished with value: 0.3700319935632785 and parameters: {'lambda_l1': 0.004313680126647664, 'lambda_l2': 0.008355812202217454}. Best is trial 49 with value: 0.36481873368079354.
regularization_factors, val_score: 0.364819: 100%|##########| 20/20 [04:48<00:00, 14.42s/it]
Early stopping, best iteration is: [38] valid_0's binary_logloss: 0.370032
min_child_samples, val_score: 0.364819: 0%| | 0/5 [00:00<?, ?it/s]
Training until validation scores don't improve for 50 rounds
min_child_samples, val_score: 0.364819: 20%|## | 1/5 [00:10<00:40, 10.19s/it][I 2024-06-18 21:19:03,252] Trial 63 finished with value: 0.3897736671401978 and parameters: {'min_child_samples': 50}. Best is trial 63 with value: 0.3897736671401978.
min_child_samples, val_score: 0.364819: 20%|## | 1/5 [00:10<00:40, 10.19s/it]
Early stopping, best iteration is: [51] valid_0's binary_logloss: 0.389774 Training until validation scores don't improve for 50 rounds
min_child_samples, val_score: 0.364819: 40%|#### | 2/5 [00:29<00:46, 15.39s/it][I 2024-06-18 21:19:22,277] Trial 64 finished with value: 0.3683263542462511 and parameters: {'min_child_samples': 5}. Best is trial 64 with value: 0.3683263542462511.
min_child_samples, val_score: 0.364819: 40%|#### | 2/5 [00:29<00:46, 15.39s/it]
Early stopping, best iteration is: [43] valid_0's binary_logloss: 0.368326 Training until validation scores don't improve for 50 rounds
min_child_samples, val_score: 0.364819: 60%|###### | 3/5 [00:36<00:23, 11.88s/it][I 2024-06-18 21:19:29,977] Trial 65 finished with value: 0.3938280500430312 and parameters: {'min_child_samples': 100}. Best is trial 64 with value: 0.3683263542462511.
min_child_samples, val_score: 0.364819: 60%|###### | 3/5 [00:36<00:23, 11.88s/it]
Early stopping, best iteration is: [113] valid_0's binary_logloss: 0.393828 Training until validation scores don't improve for 50 rounds
min_child_samples, val_score: 0.364819: 80%|######## | 4/5 [00:53<00:13, 13.86s/it][I 2024-06-18 21:19:46,881] Trial 66 finished with value: 0.36712449039705003 and parameters: {'min_child_samples': 10}. Best is trial 66 with value: 0.36712449039705003.
min_child_samples, val_score: 0.364819: 80%|######## | 4/5 [00:53<00:13, 13.86s/it]
Early stopping, best iteration is: [32] valid_0's binary_logloss: 0.367124 Training until validation scores don't improve for 50 rounds
min_child_samples, val_score: 0.364819: 100%|##########| 5/5 [01:07<00:00, 13.80s/it][I 2024-06-18 21:20:00,561] Trial 67 finished with value: 0.3719291335673048 and parameters: {'min_child_samples': 25}. Best is trial 66 with value: 0.36712449039705003.
min_child_samples, val_score: 0.364819: 100%|##########| 5/5 [01:07<00:00, 13.50s/it]
Early stopping, best iteration is: [38] valid_0's binary_logloss: 0.371929
# save/load trainer
# dill_dump("lgbm_trainer.dill", trainer)
trainer = dill_load("lgbm_trainer.dill")
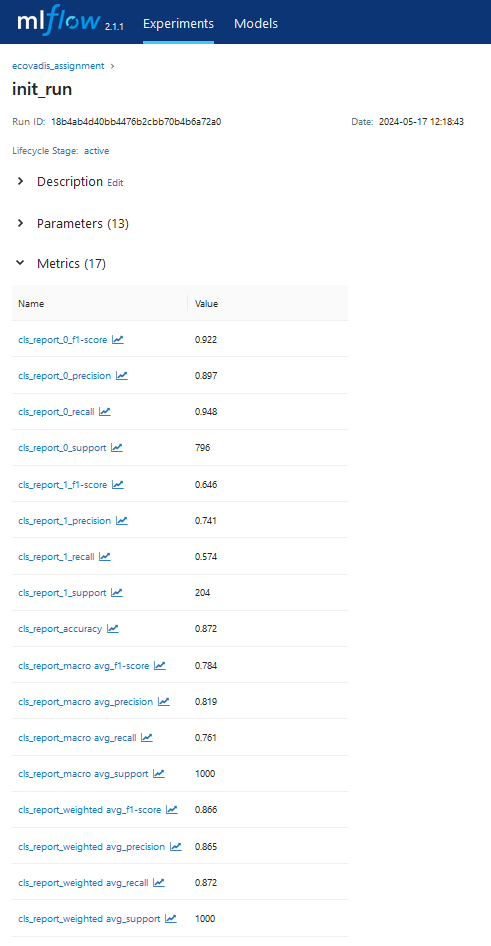
pprint(metrics_dict)
{'cls_report': {'0': {'f1-score': 0.9244823386114495,
'precision': 0.8971631205673759,
'recall': 0.9535175879396985,
'support': 796},
'1': {'f1-score': 0.6536312849162011,
'precision': 0.7597402597402597,
'recall': 0.5735294117647058,
'support': 204},
'accuracy': 0.876,
'macro avg': {'f1-score': 0.7890568117638252,
'precision': 0.8284516901538178,
'recall': 0.7635234998522022,
'support': 1000},
'weighted avg': {'f1-score': 0.8692287236576187,
'precision': 0.8691288569586443,
'recall': 0.876,
'support': 1000}},
'cm': [[759, 37], [87, 117]],
'prec_rec_curve': [[0.204, 0.7597402597402597, 1.0],
[1.0, 0.5735294117647058, 0.0],
[0.0, 1.0]]}
pprint(trainer.compute_metrics(df_test, with_dynamic_binary_threshold=True))
{'cls_report': {'0': {'f1-score': 0.9244823386114495,
'precision': 0.8971631205673759,
'recall': 0.9535175879396985,
'support': 796},
'1': {'f1-score': 0.6536312849162011,
'precision': 0.7597402597402597,
'recall': 0.5735294117647058,
'support': 204},
'accuracy': 0.876,
'macro avg': {'f1-score': 0.7890568117638252,
'precision': 0.8284516901538178,
'recall': 0.7635234998522022,
'support': 1000},
'weighted avg': {'f1-score': 0.8692287236576187,
'precision': 0.8691288569586443,
'recall': 0.876,
'support': 1000}},
'cm': [[759, 37], [87, 117]],
'prec_rec_curve': [[0.204, 0.7597402597402597, 1.0],
[1.0, 0.5735294117647058, 0.0],
[0.0, 1.0]]}
Mlflow¶
- tracking
- model registration in Minio
mlflow_host = "10.152.183.54"
mlflow_host_url = "mlflow.mlflow.svc.cluster.local"
mlflow_port = "5000"
os.environ["AWS_ACCESS_KEY_ID"] = "minioadmin"
os.environ["AWS_SECRET_ACCESS_KEY"] = "minioadmin"
os.environ["MLFLOW_S3_ENDPOINT_URL"] = f"http://10.152.183.156:9000"
mlflow.set_tracking_uri("http://" + mlflow_host + ":" + mlflow_port)
experiment_id = get_or_create_experiment("ecovadis")
mlflow.set_experiment(experiment_id=experiment_id)
<Experiment: artifact_location='s3://mlflow/6', creation_time=1718745770093, experiment_id='6', last_update_time=1718745770093, lifecycle_stage='active', name='ecovadis', tags={}>
metrics_dict_flattened = flatten_dict(metrics_dict)
# mlflow metrics can be only int, float not list
del metrics_dict_flattened["cm"]
del metrics_dict_flattened["prec_rec_curve"]
run_name = "init_run"
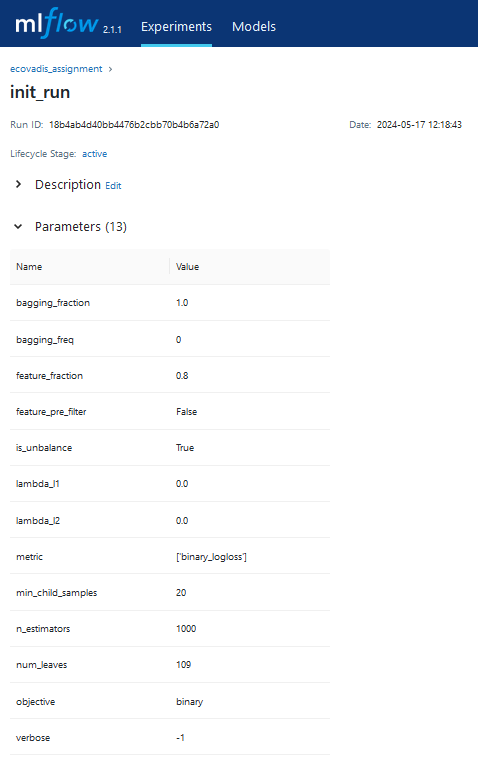
with mlflow.start_run(experiment_id=experiment_id, run_name=run_name, nested=True) as run:
mlflow.log_params(trainer.optimizer.best)
mlflow.log_metrics(metrics_dict_flattened)
# Log tags
mlflow.set_tags(
tags={
"project": "ecovadis",
"optimizer_engine": "optuna",
"model_family": "ligtgbm",
"feature_set_version": 1,
}
)
# Log figure - for future fun
# mlflow.log_figure(figure=correlation_plot, artifact_file="correlation_plot.png")
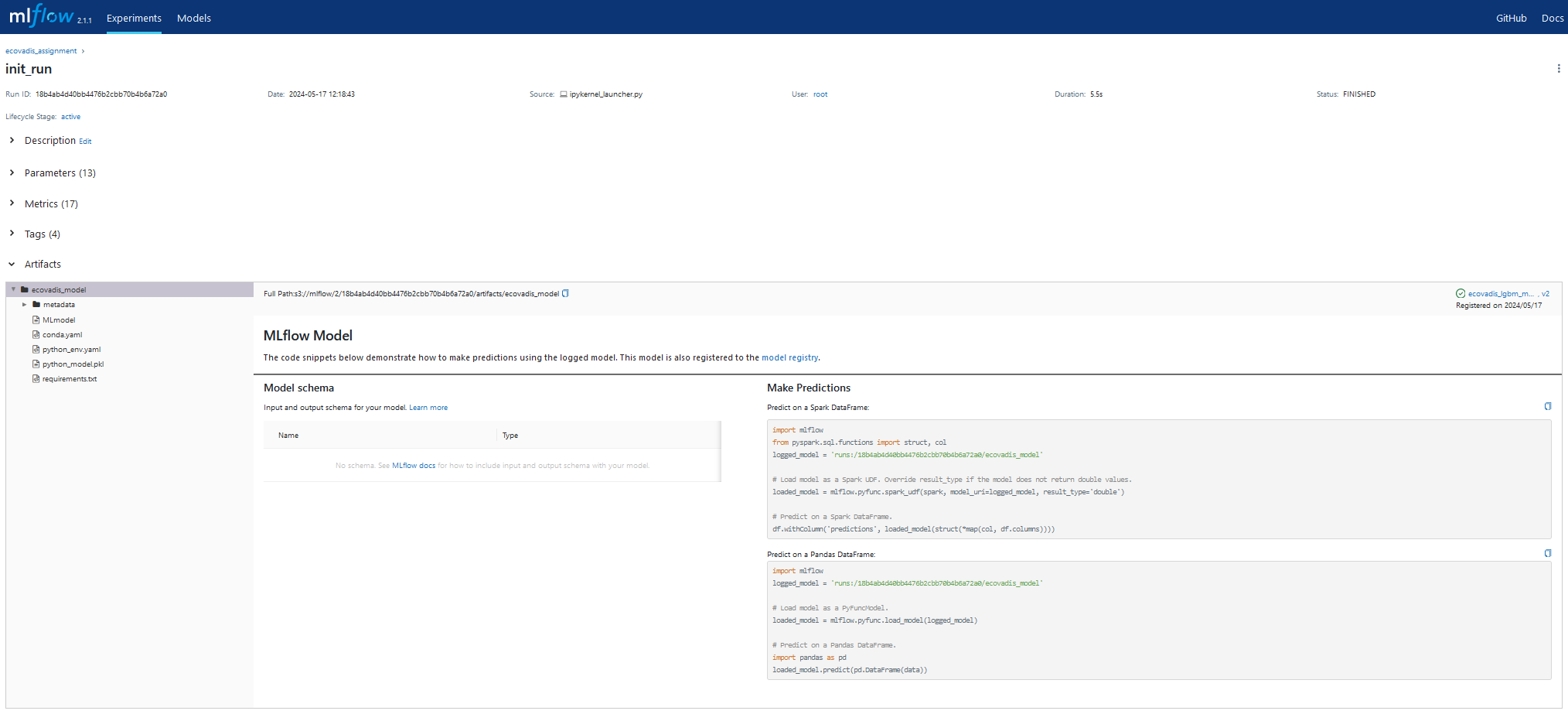
artifact_path = "ecovadis_model"
registered_model_name = "ecovadis_lgbm_model"
mlflow.pyfunc.log_model(python_model=trainer,
artifact_path=artifact_path,
registered_model_name=registered_model_name,
code_paths=["churn_pred"])
model_uri = mlflow.get_artifact_uri(artifact_path)
print(f"Run ID:\n{run.info.run_id}\nModel uri:\n{model_uri}")
2024/06/18 21:23:54 INFO mlflow.types.utils: Unsupported type hint: <class 'pandas.core.frame.DataFrame'>, skipping schema inference 2024/06/18 21:23:54 INFO mlflow.types.utils: Unsupported type hint: <class 'pandas.core.frame.DataFrame'>, skipping schema inference 2024/06/18 21:23:58 WARNING mlflow.utils.environment: Encountered an unexpected error while inferring pip requirements (model URI: /tmp/tmpfsv2c_xg/model, flavor: python_function). Fall back to return ['cloudpickle==2.2.1']. Set logging level to DEBUG to see the full traceback. Successfully registered model 'ecovadis_lgbm_model'. 2024/06/18 21:27:30 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: ecovadis_lgbm_model, version 1
Run ID: 761906b692e94248940c6dbf6b12c23c Model uri: s3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model
Created version '1' of model 'ecovadis_lgbm_model'.
Predictions testing¶
IMPORTANT: the predictions are in raw_score format(for testing to see if I get same predictions), i.e. strange numbers and not classes in the output
Example data¶
df_pd.iloc[:2]
| CustomerId | CreditScore | Country | Gender | Age | Tenure | Balance (EUR) | NumberOfProducts | HasCreditCard | IsActiveMember | EstimatedSalary | Exited | CustomerFeedback_sentiment3 | CustomerFeedback_sentiment5 | Surname_Country | Surname_Country_region | Surname_Country_subregion | Country_region | Country_subregion | is_native | Country_hemisphere | Country_gdp_per_capita | Country_IncomeGroup | Surname_Country_gdp_per_capita | Surname_Country_IncomeGroup | working_class | stage_of_life | generation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15787619 | 844 | France | Male | 18 | 2 | 160980.03 | 1 | 0 | 0 | 145936.28 | 0 | neutral | 4 stars | Taiwan | Asia | Eastern Asia | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 32756.00000 | None | working_age | teen | gen_z |
| 1 | 15770309 | 656 | France | Male | 18 | 10 | 151762.74 | 1 | 0 | 1 | 127014.32 | 0 | neutral | 1 star | United States | Americas | Northern America | Europe | Western Europe | 0 | northern | 57594.03402 | High income | 76329.58227 | High income | working_age | teen | gen_z |
df_pd.iloc[:2].transpose().to_dict(orient='index')
{'CustomerId': {0: 15787619, 1: 15770309},
'CreditScore': {0: 844, 1: 656},
'Country': {0: 'France', 1: 'France'},
'Gender': {0: 'Male', 1: 'Male'},
'Age': {0: 18, 1: 18},
'Tenure': {0: 2, 1: 10},
'Balance (EUR)': {0: 160980.03, 1: 151762.74},
'NumberOfProducts': {0: 1, 1: 1},
'HasCreditCard': {0: '0', 1: '0'},
'IsActiveMember': {0: '0', 1: '1'},
'EstimatedSalary': {0: 145936.28, 1: 127014.32},
'Exited': {0: 0, 1: 0},
'CustomerFeedback_sentiment3': {0: 'neutral', 1: 'neutral'},
'CustomerFeedback_sentiment5': {0: '4 stars', 1: '1 star'},
'Surname_Country': {0: 'Taiwan', 1: 'United States'},
'Surname_Country_region': {0: 'Asia', 1: 'Americas'},
'Surname_Country_subregion': {0: 'Eastern Asia', 1: 'Northern America'},
'Country_region': {0: 'Europe', 1: 'Europe'},
'Country_subregion': {0: 'Western Europe', 1: 'Western Europe'},
'is_native': {0: '0', 1: '0'},
'Country_hemisphere': {0: 'northern', 1: 'northern'},
'Country_gdp_per_capita': {0: 57594.03402, 1: 57594.03402},
'Country_IncomeGroup': {0: 'High income', 1: 'High income'},
'Surname_Country_gdp_per_capita': {0: 32756.0, 1: 76329.58227},
'Surname_Country_IncomeGroup': {0: 'None', 1: 'High income'},
'working_class': {0: 'working_age', 1: 'working_age'},
'stage_of_life': {0: 'teen', 1: 'teen'},
'generation': {0: 'gen_z', 1: 'gen_z'}}
after some notepad magic:
{
"CustomerId": [15787619, 15770309],
"CreditScore": [844, 656],
"Country": ["France", "France"],
"Gender": ["Male", "Male"],
"Age": [18, 18],
"Tenure": [2, 10],
"Balance (EUR)": [160980.03, 151762.74],
"NumberOfProducts": [1, 1],
"HasCreditCard": ["0", "0"],
"IsActiveMember": ["0", "1"],
"EstimatedSalary": [145936.28, 127014.32],
"Exited": [0, 0],
"CustomerFeedback_sentiment3": ["neutral", "neutral"],
"CustomerFeedback_sentiment5": ["4 stars", "1 star"],
"Surname_Country": ["Taiwan", "United States"],
"Surname_Country_region": ["Asia", "Americas"],
"Surname_Country_subregion": ["Eastern Asia", "Northern America"],
"Country_region": ["Europe", "Europe"],
"Country_subregion": ["Western Europe", "Western Europe"],
"is_native": ["0", "0"],
"Country_hemisphere": ["northern", "northern"],
"Country_gdp_per_capita": [57594.03402, 57594.03402],
"Country_IncomeGroup": ["High income", "High income"],
"Surname_Country_gdp_per_capita": [32756.0, 76329.58227],
"Surname_Country_IncomeGroup": ["None", "High income"],
"working_class": ["working_age", "working_age"],
"stage_of_life": ["teen", "teen"],
"generation": ["gen_z", "gen_z"],
}Trainer¶
trainer.predict(df=df_pd.iloc[:2].drop(columns=["Exited"]), context={})
| Exited | |
|---|---|
| 0 | -9.958064 |
| 1 | -12.560959 |
Downloaded Trainer¶
model_uri
's3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model'
# loaded_trainer = mlflow.pyfunc.load_model(model_uri)
loaded_trainer = mlflow.pyfunc.load_model('s3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model')
Downloading artifacts: 0%| | 0/61 [00:00<?, ?it/s]
loaded_trainer.unwrap_python_model()
<churn_pred.training.trainer.Trainer at 0x7f3e17f31060>
# mlflow.statsmodels.save_model(loaded_trainer, 'data/model')#, serialization_format='pickle')
mlflow.pyfunc.save_model("data/model", python_model=loaded_trainer.unwrap_python_model())
2024/06/18 21:31:34 INFO mlflow.types.utils: Unsupported type hint: <class 'pandas.core.frame.DataFrame'>, skipping schema inference 2024/06/18 21:31:34 INFO mlflow.types.utils: Unsupported type hint: <class 'pandas.core.frame.DataFrame'>, skipping schema inference 2024/06/18 21:31:37 WARNING mlflow.utils.environment: Encountered an unexpected error while inferring pip requirements (model URI: data/model, flavor: python_function). Fall back to return ['cloudpickle==2.2.1']. Set logging level to DEBUG to see the full traceback.
loaded_trainer.predict(df_pd.iloc[:2].drop(columns=["Exited"]))
| Exited | |
|---|---|
| 0 | -9.958064 |
| 1 | -12.560959 |
Downloaded/Served Trainer¶
- i.e. testing model locally
model_uri
's3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model'
! mlflow models serve -m "s3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model" --env-manager local -p 5000
Downloading artifacts: 100%|███████████████████| 61/61 [00:00<00:00, 691.42it/s]
2024/06/18 21:32:14 INFO mlflow.models.flavor_backend_registry: Selected backend for flavor 'python_function'
Downloading artifacts: 100%|███████████████████| 61/61 [00:00<00:00, 304.59it/s]
2024/06/18 21:32:15 INFO mlflow.pyfunc.backend: === Running command 'exec gunicorn --timeout=60 -b 127.0.0.1:5000 -w 1 ${GUNICORN_CMD_ARGS} -- mlflow.pyfunc.scoring_server.wsgi:app'
[2024-06-18 21:32:15 +0000] [1380] [INFO] Starting gunicorn 22.0.0
[2024-06-18 21:32:15 +0000] [1380] [INFO] Listening at: http://127.0.0.1:5000 (1380)
[2024-06-18 21:32:15 +0000] [1380] [INFO] Using worker: sync
[2024-06-18 21:32:15 +0000] [1381] [INFO] Booting worker with pid: 1381
^C
[2024-06-18 21:36:45 +0000] [1380] [INFO] Handling signal: int
[2024-06-18 21:36:45 +0000] [1381] [INFO] Worker exiting (pid: 1381)
output from terminal:
root@jupyter-5uperpalo:~/assignment/ecovadis_assignment# curl -X POST -H "Content-Type:application/json" --data '{"inputs": {"CustomerId": [15787619, 15770309], "CreditScore": [844, 656], "Country": ["France", "France"], "Gender": ["Male", "Male"], "Age": [18, 18], "Tenure": [2, 10], "Balance (EUR)": [160980.03, 151762.74], "NumberOfProducts": [1, 1], "HasCreditCard": ["0", "0"], "IsActiveMember": ["0", "1"], "EstimatedSalary": [145936.28, 127014.32], "CustomerFeedback_sentiment3": ["neutral", "neutral"], "CustomerFeedback_sentiment5": ["4 stars", "1 star"], "Surname_Country": ["Taiwan", "United States"], "Surname_Country_region": ["Asia", "Americas"], "Surname_Country_subregion": ["Eastern Asia", "Northern America"], "Country_region": ["Europe", "Europe"], "Country_subregion": ["Western Europe", "Western Europe"], "is_native": ["0", "0"], "Country_hemisphere": ["northern", "northern"], "Country_gdp_per_capita": [57594.03402, 57594.03402], "Country_IncomeGroup": ["High income", "High income"], "Surname_Country_gdp_per_capita": [32756.0, 76329.58227], "Surname_Country_IncomeGroup": ["None", "High income"], "working_class": ["working_age", "working_age"], "stage_of_life": ["teen", "teen"], "generation": ["gen_z", "gen_z"]}}' http://127.0.0.1:5000/invocations
{"predictions": [{"Exited": -9.958063834023024}, {"Exited": -12.560959268044444}]}Model deployment using Kserve + Knative + Istio¶
reasons:
- Kserve is less mature than Seldon core but is primarly adopted by Kubeflow and MLflow
- "Serverless installation using Knative" is a primary installation option of Ksserve as KServe Serverless installation enables autoscaling based on request volume and supports scale down to and from zero. It also supports revision management and canary rollout based on revisions.
- Istio is a primary choice of service routing for Knative
- Kserve uses MLserver from Seldoncore but according to "quick internet search" it is adopted more by community than Seldon-core as Seldon-core focuses more on enterprise version of its software
issues:
- Kserve uses MLserver which ignores
requirements.txtand needs prepackaged conda environment in tar.gz file - Kserve uses old version of MLserver(1.3.2) resulting in incorrect usage of
conda-unpack - related code has to be included with model and conda environment
- mlserver with correct version has to be defined in the conda env:
- mlserver==1.3.5 - mlserver-mlflow==1.3.5
related github issue discussions/troubleshooting:
Create conda environment, tar.gz it and upload it to Minio¶
from minio import Minio
# to download conda.yaml
client = Minio("10.152.183.156:9000", "minioadmin", "minioadmin", secure=False)
bucket = "mlflow"
object_name = "6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model/conda.yaml"
file_path = "notebooks/conda.yaml"
client.fget_object(bucket_name=bucket, object_name=object_name, file_path=file_path)
<minio.datatypes.Object at 0x730858235e70>
following commands were run in terminal to create environment:
pip install conda_pack
conda env create --force -f conda.yaml
conda-pack --name mlflow-env --output environment.tar.gz --force --ignore-editable-packages --ignore-missing-files# upload environmnet.tar.gz
object_name = "6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model/environment.tar.gz"
file_path = "notebooks/environment.tar.gz"
client.fput_object(bucket_name=bucket, object_name=object_name, file_path=file_path)
<minio.helpers.ObjectWriteResult at 0x7f409c5bbac0>
Create Kserver Inference Service in Kubernetes¶
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "custom-ecovadis-model"
namespace: "mlflow-kserve-success6g"
spec:
predictor:
serviceAccountName: success6g
model:
modelFormat:
name: mlflow
protocolVersion: v2
storageUri: "s3://mlflow/6/761906b692e94248940c6dbf6b12c23c/artifacts/ecovadis_model"Test the Inference service¶
export INGRESS_NAME=istio-ingressgateway
export INGRESS_NS=istio-system
export INGRESS_PORT=$(kubectl -n "${INGRESS_NS}" get service "${INGRESS_NAME}" -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n "${INGRESS_NS}" -o jsonpath='{.items[0].status.hostIP}')
export SERVICE_HOSTNAME=$(kubectl get inferenceservice custom-ecovadis-model -n mlflow-kserve-success6g -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d @./test.json \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/custom-ecovadis-model/inferSUMMARY¶
This unfortunately crashes due to the size of conda environment that is being downloaded from minio database by Kserve. COnda env has 3.36GB due to language models (libraries).
Note: this approach was succesfully tested on a custom model that used small conda env ~360MB
WORKAROUND¶
- save/serve(deploy) only the LightGBM model
- preprocess the data locally; this could be done in production using (i) Kserve InferenceGpraph or (ii) pipelines in Kubeflow
- send preprocessed data to API
run_name = "init_run"
with mlflow.start_run(experiment_id=experiment_id, run_name=run_name, nested=True) as run:
mlflow.log_params(trainer.optimizer.best)
mlflow.log_metrics(metrics_dict_flattened)
# Log tags
mlflow.set_tags(
tags={
"project": "ecovadis",
"optimizer_engine": "optuna",
"model_family": "ligtgbm",
"feature_set_version": 1,
}
)
# Log figure - for future fun
# mlflow.log_figure(figure=correlation_plot, artifact_file="correlation_plot.png")
artifact_path = "ecovadis_raw_model"
registered_model_name = "ecovadis_raw_lgbm_model"
mlflow.lightgbm.log_model(
lgb_model=trainer.model,
artifact_path=artifact_path,
registered_model_name=registered_model_name)
# mlflow.pyfunc.log_model(python_model=trainer,
# artifact_path=artifact_path,
# registered_model_name=registered_model_name,
# code_paths=["churn_pred"])
model_uri = mlflow.get_artifact_uri(artifact_path)
print(f"Run ID:\n{run.info.run_id}\nModel uri:\n{model_uri}")
Successfully registered model 'ecovadis_raw_lgbm_model'. 2024/06/19 05:43:13 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: ecovadis_raw_lgbm_model, version 1
Run ID: 9a74f8e9087044b9b9d4935a268c26d0 Model uri: s3://mlflow/6/9a74f8e9087044b9b9d4935a268c26d0/artifacts/ecovadis_raw_model
Created version '1' of model 'ecovadis_raw_lgbm_model'.
df_infser_test = df_pd.iloc[:2]
for prep in trainer.preprocessors:
df_infser_test = prep.transform(df_infser_test)
if hasattr(trainer, "optimizer"):
if hasattr(trainer.optimizer, "best_to_drop"): # type: ignore
df_infser_test.drop(
columns=trainer.optimizer.best_to_drop, # type: ignore
inplace=True,
)
df_infser_test = df_infser_test.drop(columns=trainer.id_cols + [trainer.target_col])
df_infser_test.transpose().to_dict(orient='index')
{'is_native': {0: 1.0, 1: 1.0},
'generation': {0: 1.0, 1: 1.0},
'Surname_Country': {0: 1.0, 1: 2.0},
'Country_subregion': {0: 1.0, 1: 1.0},
'Surname_Country_subregion': {0: 1.0, 1: 2.0},
'Surname_Country_IncomeGroup': {0: 1.0, 1: 2.0},
'stage_of_life': {0: 1.0, 1: 1.0},
'IsActiveMember': {0: 1.0, 1: 2.0},
'Country': {0: 1.0, 1: 1.0},
'CustomerFeedback_sentiment5': {0: 1.0, 1: 2.0},
'CustomerFeedback_sentiment3': {0: 1.0, 1: 1.0},
'Gender': {0: 1.0, 1: 1.0},
'Surname_Country_region': {0: 1.0, 1: 2.0},
'working_class': {0: 1.0, 1: 1.0},
'HasCreditCard': {0: 1.0, 1: 1.0},
'EstimatedSalary': {0: 145936.28125, 1: 127014.3203125},
'Age': {0: 18.0, 1: 18.0},
'Tenure': {0: 2.0, 1: 10.0},
'NumberOfProducts': {0: 1.0, 1: 1.0},
'Country_gdp_per_capita': {0: 57594.03515625, 1: 57594.03515625},
'Surname_Country_gdp_per_capita': {0: 32756.0, 1: 76329.5859375},
'CreditScore': {0: 844.0, 1: 656.0},
'Balance (EUR)': {0: 160980.03125, 1: 151762.734375}}
create test.json:
cat test.json
{
"parameters": {
"content_type": "pd"
},
"inputs": [
{
"name": "is_native",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "generation",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Surname_Country",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Country_subregion",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Surname_Country_subregion",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Surname_Country_IncomeGroup",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "stage_of_life",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "IsActiveMember",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Country",
"shape": [1],
"datatype": "BYTES",
"data": [1.0]
},
{
"name": "CustomerFeedback_sentiment5",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "CustomerFeedback_sentiment3",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Gender",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Surname_Country_region",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "working_class",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "HasCreditCard",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "EstimatedSalary",
"shape": [1],
"datatype": "FP64",
"data": [145936.28]
},
{
"name": "Age",
"shape": [1],
"datatype": "FP64",
"data": [18]
},
{
"name": "Tenure",
"shape": [1],
"datatype": "FP64",
"data": [2]
},
{
"name": "NumberOfProducts",
"shape": [1],
"datatype": "FP64",
"data": [1.0]
},
{
"name": "Country_gdp_per_capita",
"shape": [1],
"datatype": "FP64",
"data": [57594.03402]
},
{
"name": "Surname_Country_gdp_per_capita",
"shape": [1],
"datatype": "FP64",
"data": [32756.0]
},
{
"name": "CreditScore",
"shape": [1],
"datatype": "FP64",
"data": [844.0]
},
{
"name": "Balance (EUR)",
"shape": [1],
"datatype": "FP64",
"data": [160980.03125]
}
]test service:
export INGRESS_NAME=istio-ingressgateway
export INGRESS_NS=istio-system
export SERVICE_HOSTNAME=custom-ecovadis-raw-model.mlflow-kserve-success6g.example.com
export INGRESS_PORT=$(kubectl -n "${INGRESS_NS}" get service "${INGRESS_NAME}" -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
export SERVICE_HOSTNAME=$(kubectl get inferenceservice custom-ecovadis-raw-model -n mlflow-kserve-success6g -o jsonpath='{.status.url}' | cut -d "/" -f 3)
curl -v \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d @./test.json \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/custom-ecovadis-raw-model/inferoutput:
{INGRESS_HOST}:${INGRESS_PORT}/v2/models/custom-ecovadis-raw-model/infer
* Trying 10.1.24.50:32702...
* Connected to 10.1.24.50 (10.1.24.50) port 32702 (#0)
> POST /v2/models/custom-ecovadis-raw-model/infer HTTP/1.1
> Host: custom-ecovadis-raw-model.mlflow-kserve-success6g.example.com
> User-Agent: curl/8.1.1
> Accept: */*
> Content-Type: application/json
> Content-Length: 2823
>
< HTTP/1.1 200 OK
< ce-endpoint: custom-ecovadis-raw-model
< ce-id: 0cd6e630-3a2b-44de-8284-299a10cf5283
< ce-inferenceservicename: mlserver
< ce-modelid: custom-ecovadis-raw-model
< ce-namespace: mlflow-kserve-success6g
< ce-requestid: 0cd6e630-3a2b-44de-8284-299a10cf5283
< ce-source: io.seldon.serving.deployment.mlserver.mlflow-kserve-success6g
< ce-specversion: 0.3
< ce-type: io.seldon.serving.inference.response
< content-length: 251
< content-type: application/json
< date: Wed, 19 Jun 2024 06:49:46 GMT
< server: istio-envoy
< x-envoy-upstream-service-time: 712
<
* Connection #0 to host 10.1.24.50 left intact
{"model_name":"custom-ecovadis-raw-model","id":"0cd6e630-3a2b-44de-8284-299a10cf5283","parameters":{"content_type":"np"},"outputs":[{"name":"output-1","shape":[1,1],"datatype":"FP64","parameters":{"content_type":"np"},"data":[-9.958064]}]}